Prosody-controllable spontaneous TTS with neural HMMs
This project is maintained by Hfkml
Prosody-controllable spontaneous TTS with neural HMMs
Harm Lameris,Shivam Mehta, Gustav Eje Henter, Joakim Gustafson, and Éva Székely
This page presents listening examples for our TTS architecture Prosody-controllable spontaneous TTS with neural HMMs. Code will be made available soon!
Summary
Spontaneous speech has many affective and pragmatic functions that are interesting and challenging to model in TTS (text-to-speech). However, the presence of reduced articulation, fillers, repetitions, and other disfluencies mean that text and acoustics are less well aligned than in read speech. This is problematic for attention-based TTS. We propose a TTS architecture that is particularly suited for rapidly learning to speak from irregular and small datasets while also reproducing the diversity of expressive phenomena present in spontaneous speech. Specifically, we modify an existing neural HMM-based TTS system, which is capable of stable, monotonic alignments for spontaneous speech, and add utterance-level prosody control, so that the system can represent the wide range of natural variability in a spontaneous speech corpus. We objectively evaluate control accuracy and perform a subjective listening test to compare to a system without prosody control. To exemplify the power of combining mid-level prosody control and ecologically valid data for reproducing intricate spontaneous speech phenomena, we evaluate the system’s capability of synthesizing two types of creaky phonation.
| System | MOS | Confidence Interval |
|---|---|---|
| NHMM | 3.60 | [3.51, 3.69] |
| Proposed | 3.48 | [3.40, 3.57] |
Code
Code is available in our GitHub repository, along with pre-trained models.
Stimuli from the listening tests
| Text | Prosodically modified | Non-modified |
|---|---|---|
| In the pub, you know, it's just a lot of people just like talking, and it is difficult to connect. | ||
| On a cold night in Dublin, the streets sometimes seem devoid of people. | ||
| I think that there is another, better way of solving it, if you think it through for a moment. | ||
| I always think it's important to be able to explain stuff that's difficult to understand. | ||
| One of the things that really makes me happy, is when I listen to music while walking in the rain. | ||
| You need to realize that these characteristics do not necessarily define you. | ||
| I enjoy doing pilates, it helps me stay fit and cheerful. |
Prosody modification
Text: In the pub, you know, it’s just a lot of people just like talking, and it is difficult to connect.
| Prosodic feature | -2 | 0 | 2 |
|---|---|---|---|
| Speaking rate | |||
| Mean f0 | |||
| f0 std |
Creakiness Evaluation
| Speaker | TSGD | ||
|---|---|---|---|
| Text | No-creak | Stylistic creak | End-of-turn creak |
| There is nothing I can really do about it. | |||
| I always think it's important to be able to explain stuff that's difficult to understand. | |||
| Some words of advice for a new graduate: if you do not like the job, do not go. | |||
| Speaker | LJ-Speech | ||
| Text | No-creak | Stylistic creak | End-of-turn creak |
| There is nothing I can really do about it. | |||
| I always think it's important to be able to explain stuff that's difficult to understand. | |||
| Some words of advice for a new graduate: if you do not like the job, do not go. | |||
Screenshot of the MUSHRA like CMOS evaluation interface
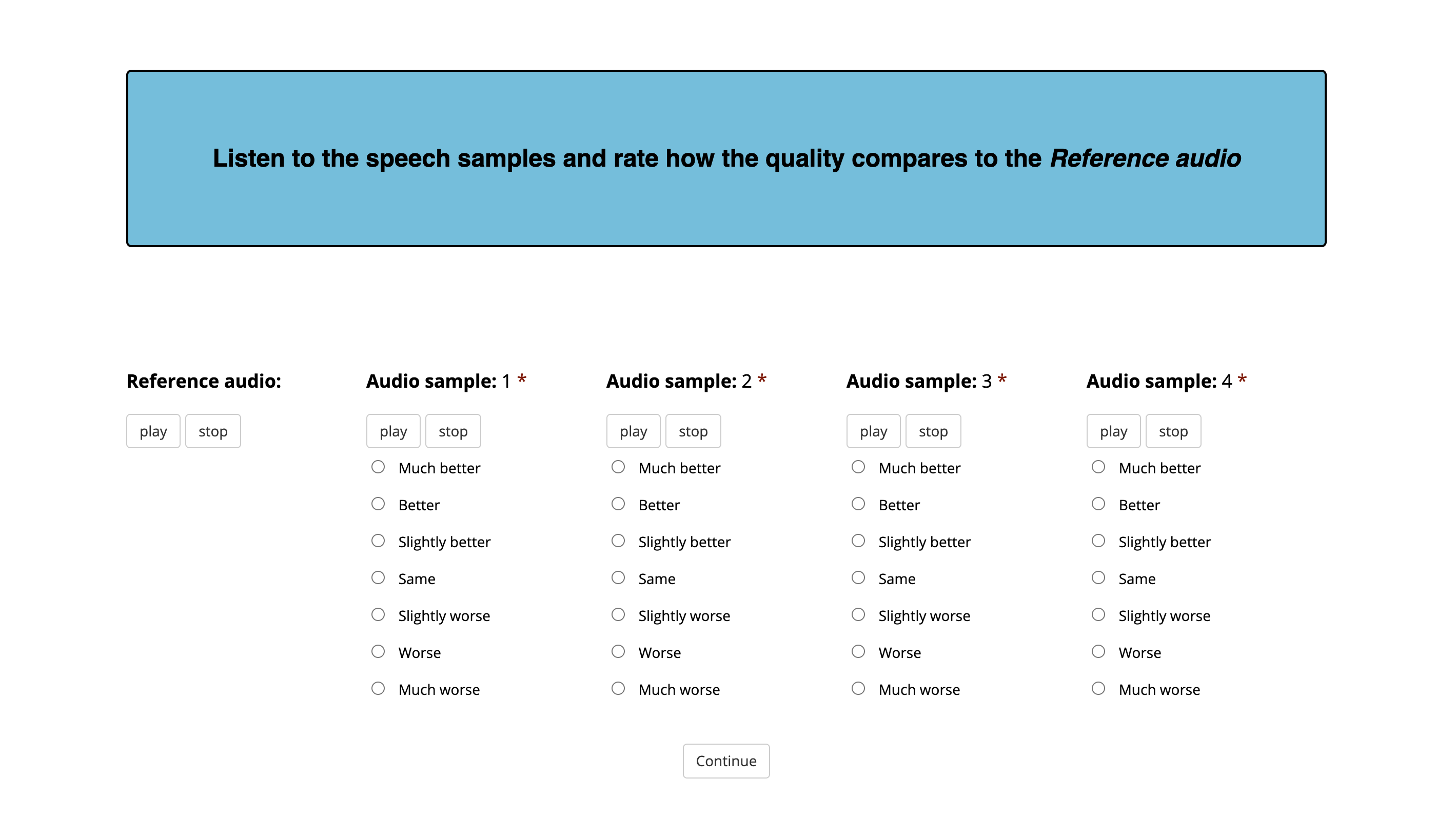
Stimuli from the MUSHRA like CMOS evaluation
Text: There are many different types of salad.
| F0 | ||||
|---|---|---|---|---|
| Reference | -1.5 | -0.5 | 0.5 | 1.5 |
| F0 Std | ||||
| Reference | -1.5 | -0.5 | 0.5 | 1.5 |
| SR | ||||
| Reference | -1.5 | -0.5 | 0.5 | 1.5 |